Quinsy Brenda
November 8, 2023
From Tableau to D3 to Plotly to Matplotlib, there’s a dizzying array of data visualisation tools to choose from. Quinsy shares key considerations from a data scientist’s perspective to help you pick the right tools that help you communicate visual data insights more effectively.
Data visualisation is a bridge between raw data and meaningful insights. As a data scientist, my primary goal is to extract knowledge and tell a compelling story from a vast amount of data. By leveraging visual representations, we can uncover hidden patterns, identify trends and reveal correlations that might otherwise remain buried in the complexity of raw data. Data visualisation also facilitates effective decision-making by providing stakeholders with a visual context that is easier to comprehend and interpret.
As data scientists, we’re fortunate to have a plethora of data visualisation tools at our disposal. This abundance, however, may sometimes be overwhelming, so it’s crucial to navigate these tools strategically.
Here are my key considerations for selecting the right data visualisation tools:
Picking and choosing which data visualisation tools to use is always project-specific and requires careful consideration. Only by making the proper choices can we elevate our work to new heights.
No-code tools have gained significant popularity in recent years because of their ease of use and accessibility. These tools allow us to create beautiful visuals without requiring extensive coding knowledge. The two giants in this space are Tableau (now part of Salesforce) and Power BI from Microsoft. Other options are out there, such as Infogram and Datawrapper, but it’s important to note that these tools are more commonly used by journalists and marketing professionals, rather than being widely adopted as an industry standard in the data science field. This is because they don’t usually offer the same level of customisation and may not be as prevalent in industries outside of journalism and marketing.
Tableau is a widely used, widely recognised and highly regarded data visualisation tool that offers a suite of features for creating interactive and visually appealing visualisations. With Tableau, we’re able to connect to various data sources, transform and clean data, and build interactive dashboards and reports. With its user-friendly interface and powerful features, Tableau allows companies to effectively analyse and present data in a visually compelling manner. As of May 2023, Tableau proudly boasts a staggering 3 million profiles on Tableau Public, a platform that was introduced in 2010.
The success of Tableau can be attributed to its commitment to innovation and continuous improvement. The company regularly updates its software, introducing new features and functionalities that further enhance the user experience. Additionally, Tableau’s strong online community and extensive support resources make it easier for users to learn, collaborate, and stay up-to-date with the latest trends and best practices in data visualisation.
Screenshot of the Tableau Public Workbook by Quinsy Brenda
Here’s what I’ve learned from using Tableau so far:
While it shares similarities with Tableau, users of Microsoft products will find the Power BI option more intuitive. With Power BI, users can also connect to various data sources to build rich dashboards and presentations. Microsoft has been recognised as a Leader in the 2023 Gartner Magic Quadrant for Analytics and Business Intelligence Platforms, marking their 16th consecutive year in this position. This recognition highlights Microsoft’s ongoing commitment to innovation and delivering impactful solutions for data-driven decision-making.

Screenshot of Power BI Dashboard by Quinsy Brenda
What I’ve learned while using Power BI:
I would say no-code options are a choice backed by the industry due to their accessibility, rapid prototyping capabilities, efficiency, empowerment of non-technical users, and integration and collaboration features. These tools democratise data visualisation, enabling a broader audience to leverage data efficiently and make data-driven decisions. Perhaps you prefer using SQL to transform data and would rather not code but would like to explore different visual options? Or if you’d rather use a dashboard, then this could be the way to go.
Where no-code tools offer convenience and ease of use, their coding counterparts offer control and flexibility. Most importantly, they offer power.
Python offers a range of powerful libraries for data visualisation, including Matplotlib, Seaborn and Plotly. For those familiar with JavaScript and DOM manipulation, there is the option of using D3.js for data visualisation. Exciting, right?
Matplotlib provides tools for creating static, animated and interactive visualisations. It’s also the basic library for visualisation with Python.
Seaborn is another Python library built on top of Matplotlib, specialised in aesthetically pleasing graphs. Seaborn simplifies the process of creating plots, providing a high-level interface for generating informative and visually appealing charts. As a result, Seaborn is perfect for statistical charts.
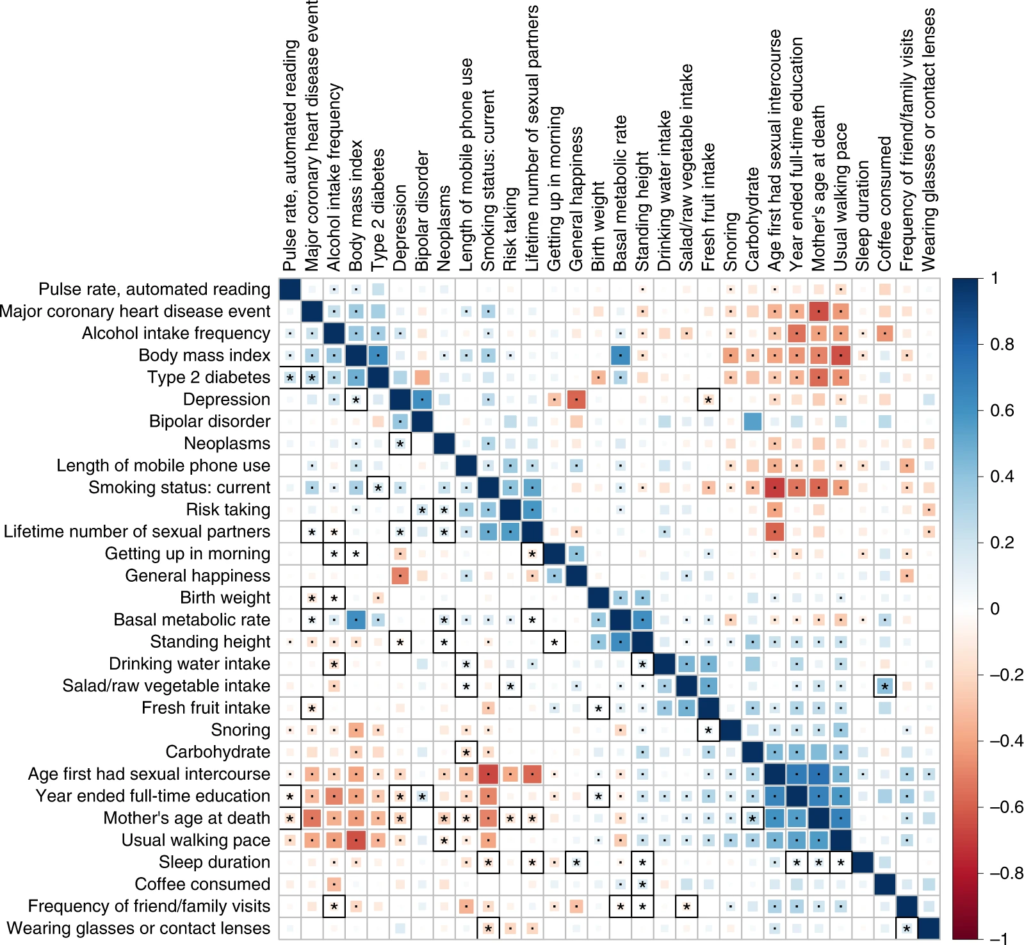
A correlation matrix shows how strong and in what direction different variables are related, as in this high-definition likelihood inference of genetic correlations across human complex traits.
The advantages of using Seaborn include:
Plotly is a versatile Python library for the creation of interactive and dynamic visualisations. It provides a high-level interface for creating interactive plots, dashboards and web interfaces, usually exported through streamlit.
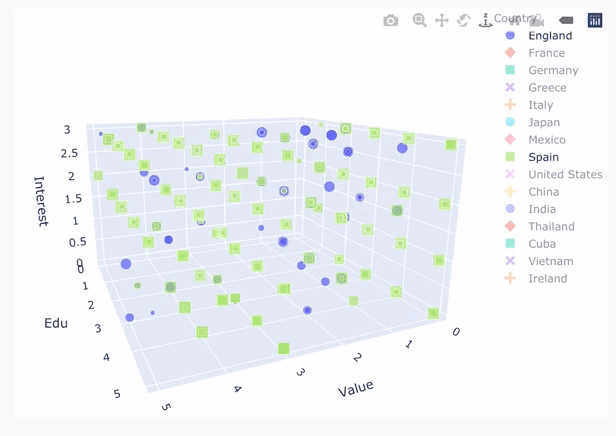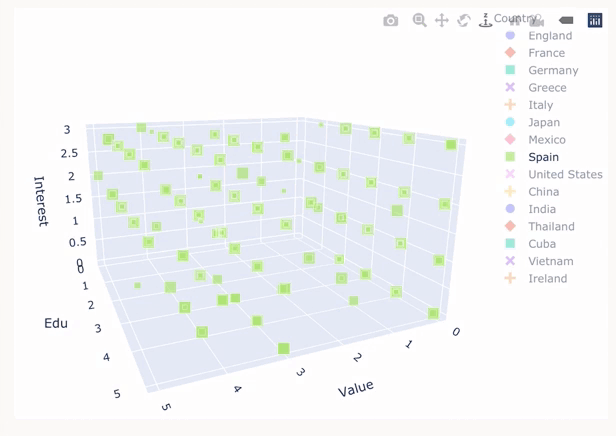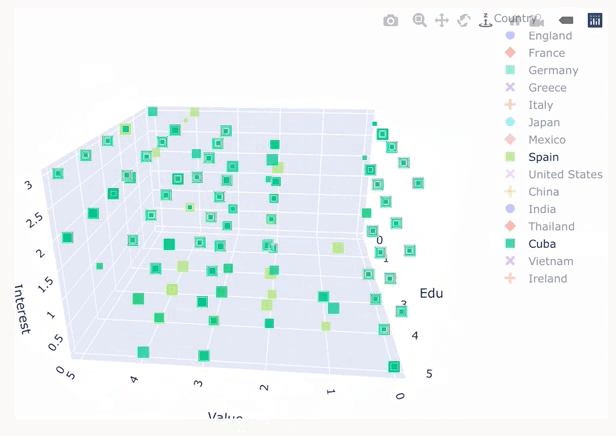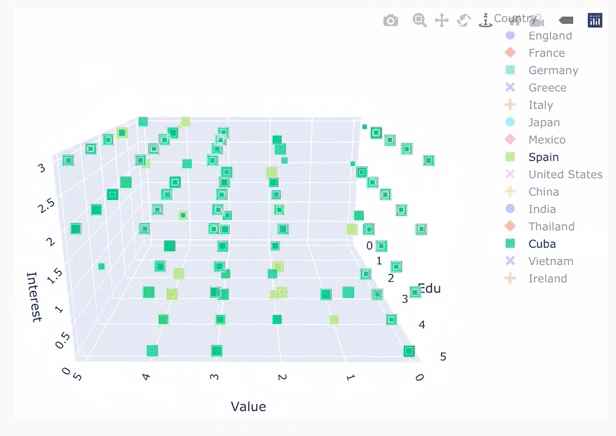
Chart created in plotly comparing rating, knowledge and interest in various country cuisines. Visualisation by Quinsy Brenda.
Plotly is an excellent choice for those who require rich interactivity in their data visualisations and want to stay within the Python ecosystem. However, D3.js is also an option for this level of interactivity.
D3.js is a powerful Javascript library for creating dynamic and interactive plots in the browser. The kinds of customisations we can do with D3.js really are endless.
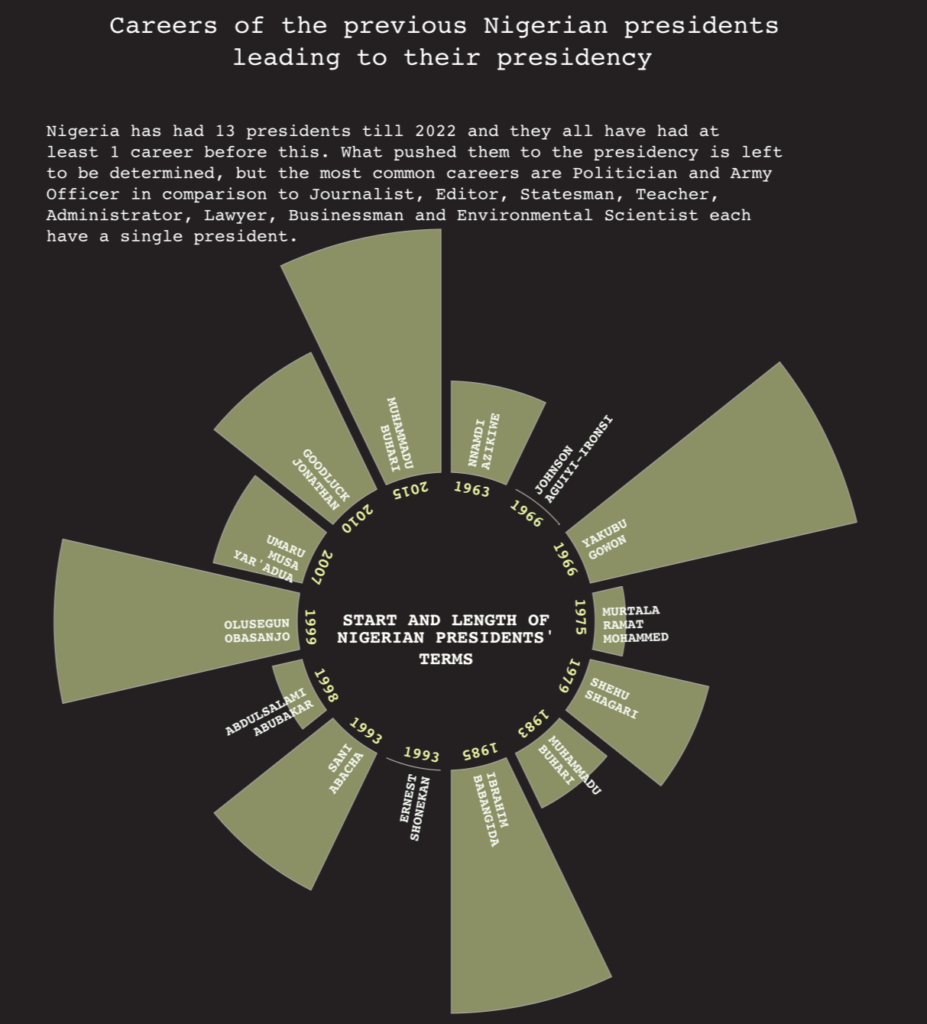
Lengths of Nigerian Presidency terms. Visualisation by Quinsy Brenda.
When it comes to code versus no-code in data visualisation, it is up to the developer which is more important: ease of use and convenience, or control, flexibility and customisation. Out of the coding options, Matplotlib stands pretty much front-and-centre for customising plots, while D3.js gives the greatest amount of customisations and interactivity, with the only downside being the need to get familiar with JavaScript.
When it comes to exploratory data analysis and quick prototyping, Python libraries like Matplotlib and Seaborn shine as they offer a wide range of visualisation options. They also provide the flexibility and customisation needed for initial data exploration.
Matplotlib allows for the creation of static and interactive visualisations, making it suitable for exploring relationships, trends and distributions in datasets.
Seaborn, meanwhile, specialises in statistical visualisations, making it ideal for tasks such as uncovering correlations, analysing distributions, and conducting multivariate analysis.
In scenarios where data scientists need to rapidly iterate and prototype visualisations to gain initial insights, Matplotlib and Seaborn offer the necessary tools and flexibility to quickly explore and visualise data.
When the goal is to create interactive dashboards or storytelling visuals that engage stakeholders and facilitate data-driven decision-making, tools like Tableau and Power BI come to the forefront because they offer a user-friendly interface, powerful data connection capabilities, and interactive features that enhance the data storytelling experience.
In scenarios where data scientists need to create interactive dashboards or storytelling visuals that engage stakeholders and provide a user-friendly experience, Tableau and Power BI offer powerful tools to achieve these goals.
For scenarios that require web-based and highly customised visualisations, tools like Plotly and D3.js emerge as the top choices. These tools provide data scientists with the flexibility to create interactive and dynamic visualisations tailored to specific needs.
Plotly’s integration with Jupyter Notebooks and its support for web-based deployment make it a suitable choice for data scientists who want to create interactive visuals that can be easily shared and embedded in web applications.
D3.js’s flexibility and extensive capabilities make it the go-to choice for those who require complete control over their visualisations and want to push the boundaries of what is possible.
In scenarios where data scientists need to create web-based and highly customised data visualisations, Plotly and D3.js offer the necessary tools to create visually stunning and interactive visuals.
A primary challenge in visualising data is striking a balance between scalability and performance. As the dataset grows, rendering visualisations becomes more taxing, and that’s where most no-code options fail. Power BI and Tableau, for example, try their best to accommodate large datasets where other options refuse large data volumes.
With a no-code visualisation tool like Datawrapper, scalability and performance can be influenced by the size and complexity of the data being analysed. Here are some considerations:
Importantly, it remains the job of the data scientist to find ways to create data visualisations that can handle the increasing volume of data without sacrificing performance. This challenge involves optimising the data processing pipelines, sampling the data, or leveraging parallel computing to maintain visual responsiveness.
Another challenge arises when balancing interactivity with the complexity and clutter of large datasets. Interactivity is essential for exploration and understanding data, allowing the user to drill into, filter and interact with the data. However, the more complex the visualisation gets, the more cluttered it becomes, making it difficult to spot patterns.
Interactivity offers a promising solution to engage users and enhance their understanding of the data as it is being presented. Interactive features empower users to explore different dimensions, filter specific variables, and customise their visual experience. This level of engagement allows users to interact with the data on a personal level, leading to deeper comprehension and more informed decision-making.
But interactivity also introduces its own set of challenges. As more interactive elements are added, there is a risk of overwhelming the user with options and controls. Excessive interactivity can lead to confusion, distraction, and ultimately a loss of focus on the core message of the visualisation. Striking the right balance between interactivity and simplicity is an art that data visualisation professionals must master.

Notice in these charts how a proper axis, fewer colours and a key remove clutter and complexity. Image by permission of Simon Rowe in Storytelling with Data.
When dealing with intricate datasets, there is an inherent temptation to include as much information as possible, resulting in cluttered and overwhelming visualisations like what we get on the left above. While these graphs may contain a treasure trove of data, their sheer complexity can hinder the viewer’s ability to extract meaningful insights.
By prioritising simplicity, clarity, and user experience, we can create visualisations that effectively communicate complex data without overwhelming the viewer. We must be mindful when creating interactive visualisations so as to properly juggle exploratory capabilities while ensuring clarity and ease of interpretation.
I find data visualisation is important to data scientists working with large datasets because:
Each data visualisation tool has its strengths and weaknesses. You might even find more strengths or more weaknesses specific to you. In this way, having a diverse portfolio of tools allows for greater flexibility and adaptability to different scenarios. A diverse data toolkit empowers us to tackle complex challenges, effectively communicate insights, and derive meaningful insights from data. It also opens doors to new opportunities and expands the possibilities for more innovative and creative visualisations.
I encourage you to embrace curiosity, push boundaries, step out of familiar tools, and experiment with new approaches. In the rapidly evolving field of data visualisation, the only constant is change. Embrace the ever-expanding array of tools and techniques available, continuously learn and adapt, and stay curious. With an open mind and an adventurous spirit, data scientists can navigate the exciting world of data visualisation and unlock the true potential of their data. Happy exploring!
Thanks to Quinsy for sharing lessons she’s learned from exploring the tools listed in this article. Creating data visualisation that brings meaningful impact at scale extends beyond choosing the right tools. It also demands the expertise of a team with diverse backgrounds in strategy, design and development. If you’re interested in how we could help your organisation do more with your data, connect with us to learn more.

Quinsy Brenda is a data scientist and web developer from Cameroon, currently based in Spain. She’s passionate about data engineering, visualisation and analysis, as they offer diverse perspectives to explore complex datasets.
Soho Works White City,
Television Centre,
101 Wood Lane,
London,
W12 7RJ