Jake Madsen
January 27, 2026

Over the next two months, we’re revisiting four pieces of work from our portfolio, flagship projects and client programmes we’ve delivered, and asking a simple question: how would we build this today?
The pace of change is real. The tools have moved on: AI, natural language interfaces, real-time pipelines, and better ways to ship prototypes into production. Work that used to take months can now move in weeks, if you’re clear on the user need and you design the system properly.
So, we’re reimagining four real problems we’ve tackled across sectors. Each one is rooted in messy, real-world constraints. Each one shows what “data intelligence, beautifully designed” looks like when you apply it to systems people actually rely on.
The point is not the tools. It’s the outcomes they now make practical: faster discovery, clearer decisions, and experiences people actually want to use.

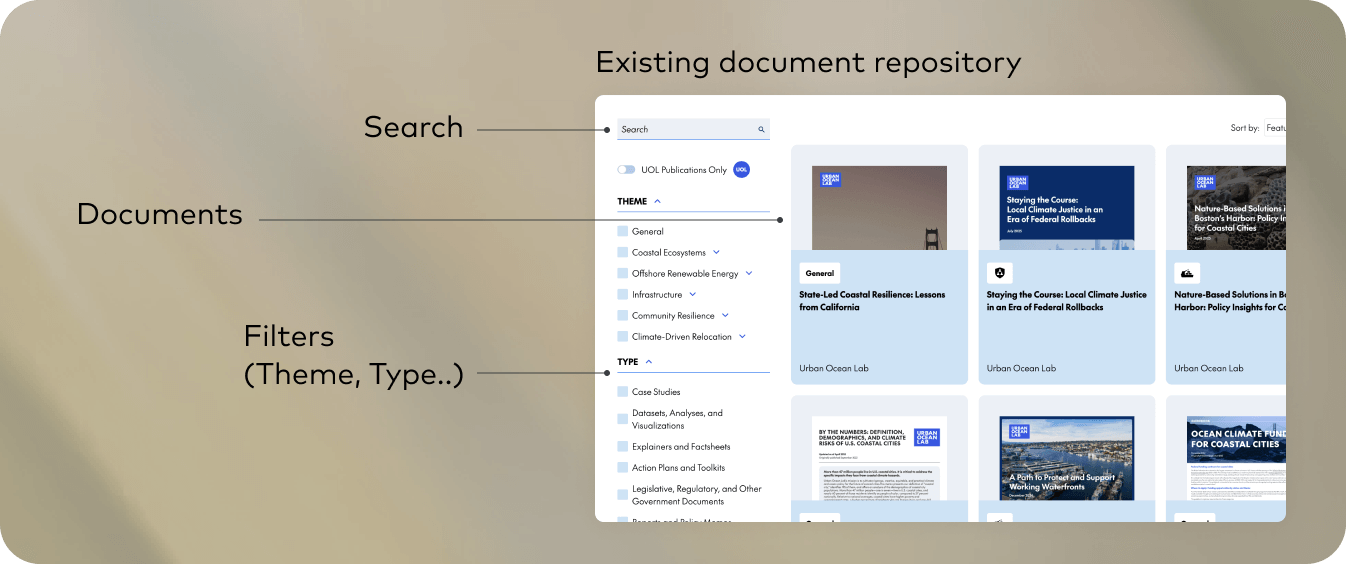
In 2023, we collaborated with Urban Ocean Lab to create a resources hub for coastal city policymakers. The platform surfaces hundreds of materials: datasets, case studies, research papers, designed to inform climate and ocean policy.
The challenge was not the quality of the content. Urban Ocean Lab had done the hard work of curating rigorous, practical research. The challenge was discovery.
How do you help a policymaker in Miami find the exact insight they need from a repository of 400+ documents?
The original solution was strong: clear categorisation, sensible tags, clean search. But it still assumes users know what they’re looking for. Often, they do not.
We’ve seen this pattern across sectors. The Partnership Against Child Exploitation faces the same challenge with protection research. Large organisations struggle with internal knowledge bases. Government departments sit on decades of policy documents that are hard to navigate.
The pain points are consistent:
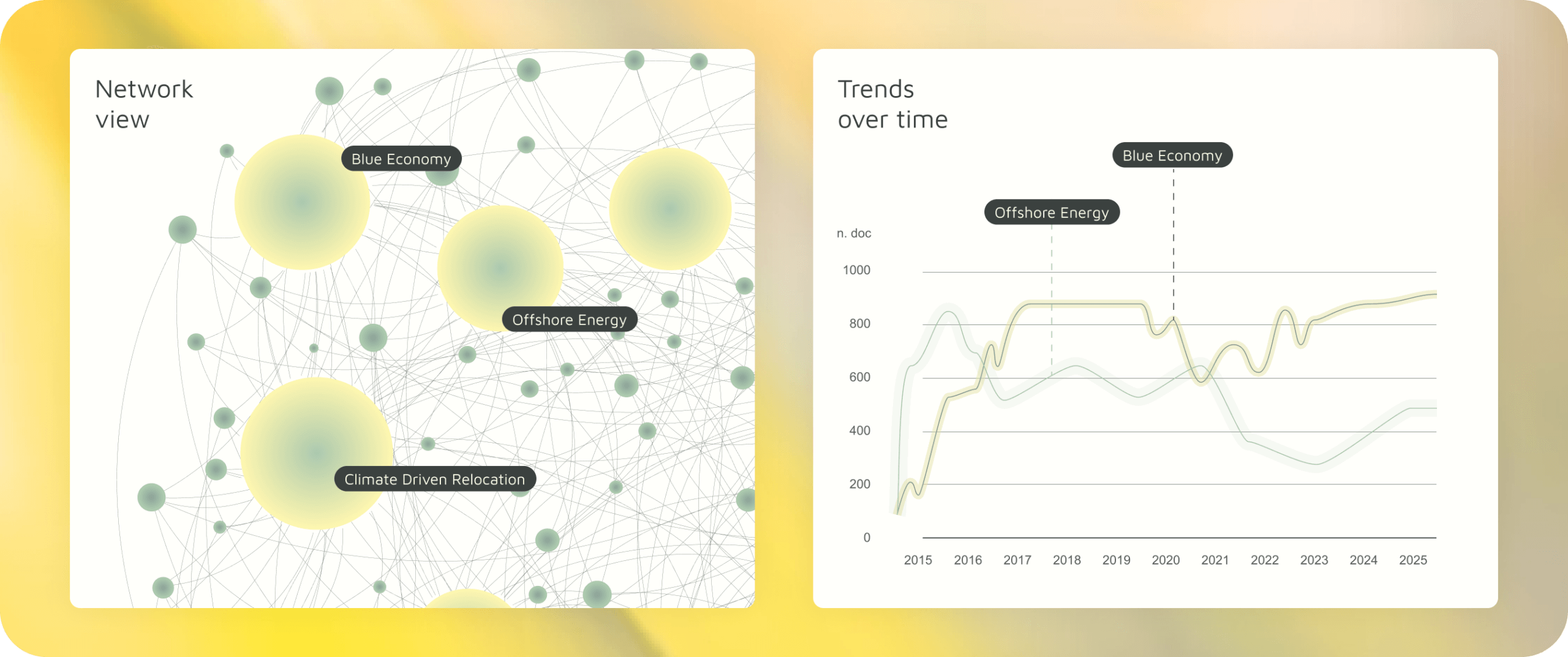
What if the corpus itself became navigable? Not just searchable, but explorable.
Here’s how we would reimagine it today:
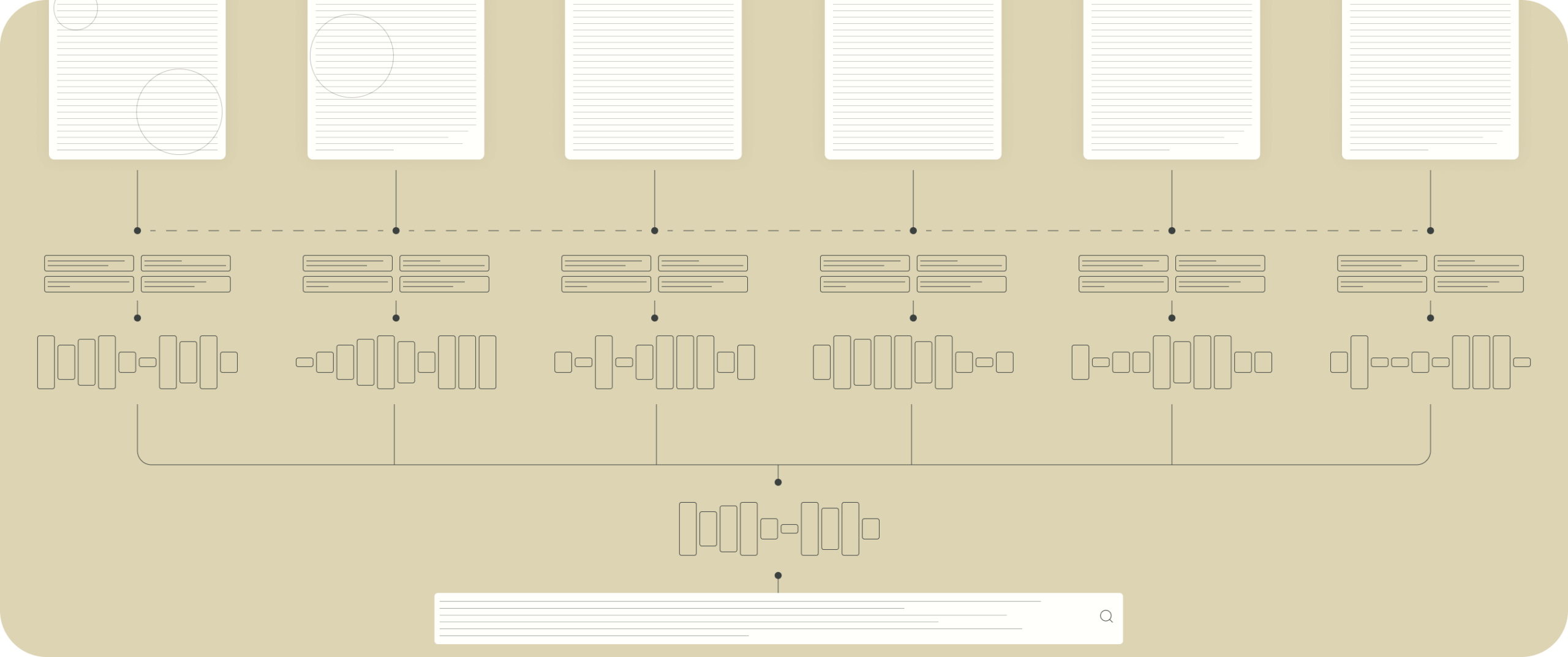
The approach is straightforward: combine proven AI services with modern data visualisation and good interface design.
We would process the document repository to extract themes and concepts, cluster documents by topic (not just manual tags), and create an interactive map of the corpus. Users can explore clusters, filter quickly, and see where to focus.
On top of that, an intelligent search layer adds contextual retrieval and synthesis. When someone asks a question, the system pulls the most relevant sources and returns a response with clear references.
This is not about inventing new technology. It’s about applying what already exists in a disciplined way, so the experience feels genuinely useful.

The gap between “organised” and “intelligent” is where most knowledge systems fail. Categorisation helps, but it rarely accelerates decision-making on its own.
Intelligence means understanding relationships between concepts, anticipating what users need next, and presenting information in ways that reduce effort and increase confidence.
This is not about replacing expertise. It’s about removing the friction that stops experts using their judgement where it counts.

Over the coming weeks, we’ll share three more reimagined projects:
If any of this feels familiar in your organisation, tell us what system you wish worked better.
Soho Works White City,
Television Centre,
101 Wood Lane,
London,
W12 7RJ